このページでは、漢字コードに関する説明をします。
文字が小さくて見づらいときには、上部の「フォントサイズ」の「大きく」をクリックすると、文字が大きくなります。
はじめに
1バイトの文字コードである ASCII だけで事が足りる英語(米語?)と違い、「漢字・かな・カタカナ (特に大量の文字がある漢字)」を扱う日本語は、1バイトで表現できる最大の数である256種類では全くコードが足りな いために、マルチバイト文字として文字コードを扱う必要があります。そして、日本語の文字コード形式は、JIS、いわゆるシフト JIS、EUC およびホストコンピューター等で使われている各メーカー固有コードなどが存在し、メーカーや OS が異なるコンピュータ間でデータ等を交換するためには各々の文字コードを変換しなければなりません。
このページは、後輩が漢字コードの変換をする必要に迫られて、わたしのところに相談にきた際に、それぞれの文字コード、そしてその文字コード間の関係がどのようになっているのかを説明するための資料として作成を始めたものです。そのため、必ずしも厳密でない説明をしているところもあったりします。この資料はあくまで取っ掛かりとして読み、概要の理解ができたところで、規格書や更に詳しい説明がしてある資料を読むようにしてください。
なお、ページの最後にこのページを記述する際に参考にした資料の一覧を「参考文献」として掲載しています。
第1章 漢字コードの規格
漢字コードは JIS 規格にて、文字位置を特定する JIS X 0208, JIS X 0212(いわゆる「区点コード表」)と符号化方式を定めた JIS X 0202 が規定されています。
漢字コードの最新規格は1998年5月1日現在、JIS X0208-1997 として定義されている「JIS 漢字コード」と、JIS X0212-1990 として定義されている「JIS 補助漢字コード」があります。なお、規格解説中に「JIS X0208-1997 規格は、JIS X0208-1990 規格に対して、文字の追加・削除・入替えなどの文字集合に対する変更は一切行っていない」とあります。これは、改正の目的が「JIS X0208-1990 のあいまいな規定を明確化し、より使いやすい規格とする(規格解説より抜粋)」ためであると説明されています。
| 制定年 | 規格名称 | 文字数 | ||
|---|---|---|---|---|
| 第一水準 | 第二水準 | 非漢字 | ||
| 1976 | JIS C 6226-1978 | 2,965 | 3,384 | 453 |
| 1983 | JIS X 0208-1983 | 2,965 | 3,388 | 524 |
| 1990 | JIS X 0208-1990 | 2,965 | 3,390 | 524 |
| 1990 | JIS X 0212-1990 | 5,801 | ||
| 1997 | JIS X 0208-1997 | 2,965 | 3,390 | 524 |
注1) JIS X 0208は、もともと JIS C 6226という名前で1978年に制定されましたが、JIS X部門(情報処理)の新設に伴ってJIS X 0208と改められました。
注2) JIS X 0212(補助漢字)には「第一水準」「第二水準」といった区分はありません。
また、JIS X0208-1997 において、初めて「いわゆる"シフト JIS もしくは MS 漢字コード"」といわれていたコード体系を附属書1として規格化し、RFC1468符号化表現(通称ISO-2022-JP としてインターネット上での電子メール、ネットワークニュース、FTP(ASCIIモード)などでの日本語テキストの符号化方法として、既に広く用いられ ている)を附属書2として規格化しています。
なお、JIS X0208-1997 附属書1では、JIS X0201 で規定される1バイトカタカナの領域を「JIS/ISO の符号化文字集合での基本原則である図形文字の一意な符号化に反する」ということで将来削除すると予告しています。1バイトカタカナコードは、DB(住所録や業務マスタ) でよく使用されているため、将来的な動向に気を配る必要があります。
- 図形文字
- 図形文字というと●とか▲とかハートマークとか罫線とかを思い浮かべるかもしれませんが、そうではなくて、制御文字に対して、アルファベット・数字・記号などの目に見える形をもった普通の文字のことです。空白は制御文字とも図形文字ともみなすことができます。
なお、注意点として、JIS の定義は最新版のみが有効であり過去のものは無効となりますが(つまり現時点ではいわゆる 97JIS のみが有効であり 78JIS 漢字コードは無効であるということ)、旧機種のパソコンやワープロで 78JIS しか使用できない環境が存在するということを考慮し、RFC1468 では ISO 2022 のエスケープシーケンスを使用し 78JIS と 83JIS との間でコード番号の入れ替えられた漢字表示を切り替える機能を提供しています。ISO 2022 のエスケープシーケンスは次の形式となります。
<ESC> <0個以上の中間文字...> <終端文字>
中間文字とは0x20~0x2Fの範囲の符号であり、終端文字とは0x30~0x7Eの範囲の符号です。
なお、エスケープシーケンスを構成する中間文字や終端文字は単なる符号であり、特定の文字集合の文字を表現するものではありませんが、便宜上 ESC$ B のようにASCII文字を用いて示すことがあります。
JISコードで使用される指示のシーケンスは以下のようになります。
| シーケンス | 内容 |
|---|---|
| <Esc>(B | ASCII(ISO/IEC646 の国際基準版)へのシフト |
| <Esc>(J | JIS ローマ字(JIS X0201 のラテン文字集合)へのシフト (1 byte カナ文字は最上位 bit が"1"となるためインターネットでは使用禁止) |
| <Esc>$@ | いわゆる 78JIS へのシフト(附属書2では JIS X0208-1997 から入れ替える文字を定義している) |
| <Esc>$B | JIS X0208-1997 へのシフト |
| <Esc>$D | JIS X0212-1990 へのシフト (補助漢字をサポートしていないシステム(シフトJIS等)では無効) |
第2章 区点コード
いわゆる「区点コード」と呼ばれているものは、コードというよりも漢字の格納位置を定めた配列と考えたほうがわかりやすいと思います。これを「符号化文字集合」といいます。符号化文字集合を定めた規格には、JIS X 0208 と JIS X 0212 があります。
2.1 JIS X 0208
私たちが普段使っている日本語の2バイトコードは、JIS X 0208 というJIS規格で規定されているものです。この規格は、日本語文で通常用いられる文字や記号(仮名・漢字・アルファベット・算用数字・各種記号など)を含み、その符号を規定しています。
2バイトの符号値は、第1・第2バイトとも0x21~0x7E(EUCでは0xA1~0xFE、以下略)ですが、JIS X 0208ではこの範囲の符号値を直接規定してはいません。JIS X 0208 では、第1バイトを区番号、第2バイトを点番号といい10進数で表現します。範囲はどちらも1~94です。したがって、1つの区は94個の点からなり、全体の符号空間は、1区1点から94区94点まで、94×94=8836文字分あります(94という数は、ISO 2022 で規定されるエンコーディングで規定されている数です)。この区番号と点番号をつなげて10進数4桁で表記したものを、俗に区点コードといいます。
表2.1-1 区点コードの例 文字 区点コード 「 」 0101 「◆」 0201 「亜」 1601
符号化文字集合内での文字の割り当ては次のようになっています。
表2.1-2 X 0208 での文字の割り当て 区 内容 1区~2区 各種記号 3区 算用数字、大小ローマ字 4区 ひらがな 5区 カタカナ 6区 大小ギリシア文字 7区 大小キリル文字 8区 罫線素片 9区~15区 未定義 16区~47区 第一水準漢字 48区~84区 第二水準漢字 85区~94区 未定義
未定義の部分に各メーカー等が独自に文字を割り当てている場合があります。このような文字は機種依存文字・ベンダー固有文字などと呼ばれ、情報交換の上で問題となっています。このような現状への反省から、JIS X 0208-1997 において、明確に未定義部分の使用は禁止されました。
なお、秀丸エディタ用のマクロ、外字チェックマクロも作ってあります。秀丸でインターネットメール等を書いているかたはご利用ください。
2.2 JIS X 0212
JIS X 0208 は広く普及していますが、それに伴って JIS X 0208に不足している文字を扱いたいとの要望も高まってきました。そこで、補助漢字 JIS X 0212が制定されました。JIS X 0212はJIS X 0208と類似の構成を持つ2バイトコードの規格です。漢字だけでなく、JIS X 0208 で不足していた記号やアルファベットなどの非漢字も含まれています。
しかし、パソコン等で使われている MS 漢字コードではこのコードを割り当てる場所が無いこと、また、汎用機などでは既に各メーカーが JIS X 0208 を独自拡張したコードがあり JIS X 0212 と多重定義となってしまう文字があること等から X 0212 を実装した環境は筆者の知る限り、日本語 EUC のみとなっています。
表2.2-1 X 0212 での文字の割り当て 区 内容 1区 未定義 2区 各種記号 3区~5区 未定義 6区 ギリシア文字補助 7区 キリル文字補助 8区 未定義 9区~11区 ラテンアルファベット補助 12区~15区 未定義 16区~77区 補助漢字 78区~94区 未定義
第3章 JISエンコーディング
JIS(漢字)コードという俗称は、次の二つの意味で使われています。
- JIS X 0208をコード空間に呼び出した状態でのビット組み合わせ
- 1 をASCIIなどと共存させるために、ISO 2022 準拠の指示のエスケープシーケンスなどを用いるエンコーディング法
たとえば、「亜という字のJISコードは0x3021だ」といった場合は前者ですし、「このHTMLファイルはJISコードを使っている」といった場合は後者です。シフトJISや日本語EUCについても同じことが言えます。
ここでは、JISエンコーディングについて、もう少し考えてみましょう。
前記のJIS X 0208 のように、実際のビット組み合わせを直接規定していない符号化文字集合を運用する場合には、符号と実際のビット組み合わせとの対応を規定する必要が生じます。また、シフト JIS において JIS 漢字コードを変換しているように、何らかの理由により符号を変換して実際のビット組み合わせを求めることもあります。このように、符号化文字集合の符号と実際のビット組み合わせとの対応を決定する方法のことを、エンコーディング法といいます。JIS では JIS X 0202 で規定しています。JIS X 0202 は ISO 2022 を日本国内の規格として規定したもので、世界の多くの符号化文字集合を対象としたエンコーディング法です。
ISO 2022 で定義されるエンコーディング法は、7単位または8単位系の符号空間(インユーステーブル(in-use table))と、G0 から G3 までの4つの中間バッファを持ち、まず、「中間バッファ」を指定し、そこへ特定の「符号化文字集合(JIS X 0208等)」を指示します(イメージ的にはロードするようなもの)。中間バッファは4種類あるので、使いたい中間バッファの全てに指示を行います。次に特定の中間バッファをインユーステーブル(7単位は GL のみ、8単位は GL, GR の2つ)へ呼び出します(イメージ的にはリンク)。使用する符号化文字集合を切り替えたい場合には「別の中間バッファを呼び出す」、「別の符号化文字集合を現在呼び出し中の中間バッファへ指定する」という方法と、「1文字だけ例外的に別の中間バッファ中の1文字を呼び出す(シングルシフト)」という方法があります。
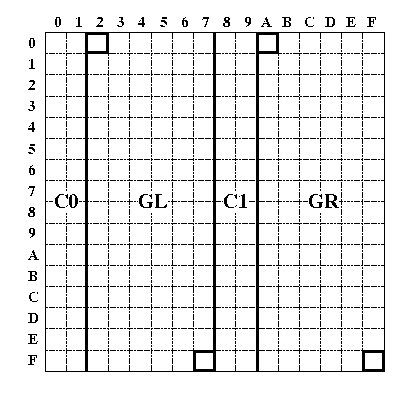
図3-1 ISO 2022 のインユーステーブル(8単位系)
概念での説明はわかりにくいので、実例を見てみましょう。
JISエンコーディングは次のようになります。
ISO 2022 に準拠したエンコーディング法で、7単位または8単位系の符号空間(インユーステーブル(in-use table))と、G0 から G3 までの4つの中間バッファを持ち、インユーステーブルおよび中間バッファを次のように使用しています。
- G0 に JIS X 0201 ローマ文字(または ASCII)を指示
- G1 に JIS X 0201 カタカナを指示
- G0 を GL に呼び出す
- JIS X 0208漢字(および他の文字集合)は G0 に指示して使用
- 7ビット環境では、JIS X 0201カタカナは、G1 を GL に呼び出すか、直接 G0 に指示して使用
- シングルシフトは使わない
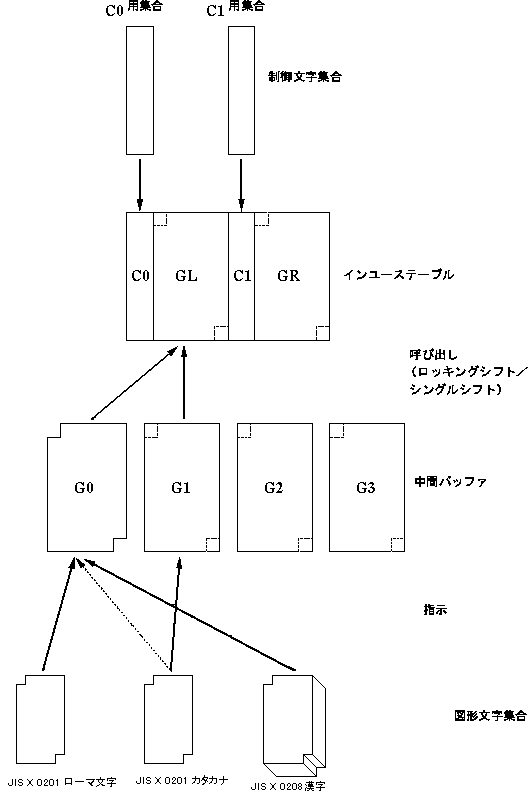
図3-2 JIS エンコーディング の構造(8単位系)
呼び出しの制御機能の表現は、C0 制御文字・C1 制御文字・単独の制御機能と多岐にわたっています。単独の制御機能とは、制御文字集合に含まれない制御機能をエスケープシーケンス ESC 0x60~0x7E で表現するものです。
| 制御機能 | 符号 | 符号の区分 | |
|---|---|---|---|
| ロッキングシフト(左) | SI/LS0 | 0x0F | C0 制御文字 |
| SO/LS1 | 0x0E | ||
| LS2 | ESC 0x6E | 単独の制御機能 | |
| LS3 | ESC 0x6F | ||
| ロッキングシフト(右) | LS1R | ESC 0x7E | 単独の制御機能 |
| LS2R | ESC 0x7D | ||
| LS3R | ESC 0x7C | ||
| シングルシフト | SS2 | 0x8E | C1制御文字 |
| SS3 | 0x8F | ||
JIS エンコーディングでは、区または点番号の1~94は、0x21~0x7Eとして表現されます。
| 文字 | 区点コード | 符号値 |
|---|---|---|
| 「 」 | 0101 | 0x2121 |
| 「◆」 | 0201 | 0x2221 |
| 「亜」 | 1601 | 0x3021 |
ちなみに、ASCIIコードは次のように規定されており、0x21~0x7Eは印字可能文字となります。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | <NUL> | <DLE> | <SP> | 0 | @ | P | ` | p |
| 1 | <SOH> | <DC1> | ! | 1 | A | Q | a | q |
| 2 | <STX> | <DC2> | " | 2 | B | R | b | r |
| 3 | <ETX> | <DC3> | # | 3 | C | S | c | s |
| 4 | <EOT> | <DC4> | $ | 4 | D | T | d | t |
| 5 | <ENQ> | <NAK> | % | 5 | E | U | e | u |
| 6 | <ACK> | <SYN> | & | 6 | F | V | f | v |
| 7 | <BEL> | <ETB> | ' | 7 | G | W | g | w |
| 8 | <BS> | <CAN> | ( | 8 | H | X | h | x |
| 9 | <HT> | <EM> | ) | 9 | I | Y | i | y |
| A | <LF> | <SUB> | * | : | J | Z | j | z |
| B | <VT> | <ESC> | + | ; | K | [ | k | { |
| C | <FF> | <FS> | , | < | L | \ | l | | |
| D | <CR> | <GS> | - | = | M | ] | m | } |
| E | <SO> | <RS> | . | > | N | ^ | n | ~ |
| F | <SI> | <US> | / | ? | O | _ | o | <DEL> |
JIS コードの利点の一つは、7ビットの伝送路でも伝送できることです。また、エスケープシーケンス中の<Esc>を除けば前記のとおりASCIIコードの印字可能文字として認識することもできます。未だに7ビットの伝送路が残るインターネットのメールやニュースでJIS コードが使われている理由もここにあります。しかし、エスケープシーケンスの存在が厄介ですので、コンピュータ内部のデータ処理ではあまり使われません。
e.g. 文字列「かな漢字a」をJIS X 0202(ISO 2022)に従い符号化すると次のようになります。
| 文字列 | かな漢字a |
| エスケープシーケンス | <Esc>$Bかな漢字<Esc>(Ja |
| コード値 | 1B 24 42 242B 244A 3441 3B7A 1B 28 4A 61 |
| ASCII文字 | .$B$+$J4A;z.(Ja |
※ASCII文字で表示できないコードは"."とした
動作の説明は次のようになります。
- エスケープシーケンスにより「G0 にJIS X 0208-1997」を指示 (G0 の呼び出しは既に行われていると仮定)
- 第一バイトの"24"から"4区"が指定された事を認識
- 第二バイトの"2B"から"11点"が指定された事を認識 (文字"か")
- ...略...
- エスケープシーケンスにより「G0 にJIS X 0201 ラテン文字集合」を指示
- "61"を認識 (文字"a")
第4章 いわゆるシフトJISコード(MS漢字コード)
シフトJISは、言うまでもなくISO 2022 非準拠です。
マイクロソフト社など数社が開発したシフト JIS は、JIS X 0201・JIS X 0208という2つの符号化文字集合を対象としたエンコーディング法で、エスケープシーケンスを使用せずに2バイトコード文字を混在させることができます。しかし、これらの文字を構成している2バイトのうち第2バイトのなかに ASCII 文字と重複するものが存在します。また、シフト JIS は、JIS X 0212 で定義されている「補助漢字」をサポートしていません。これは、単純にこれらの文字を収められるだけのコード空間が無いためです。
シフト JIS のエンコードは次のようなものです。
0x81~0x9F または 0xE0~0xEF のバイトによって2バイトコードの始まりとする。そしてこのバイトは、そこから始まる2バイトコードの第1バイトとして処理を行う。続く第2バイトは、0x40~0x7E または 0x80~0xFC の範囲を持つ値となっています。
長所をまとめると、エスケープシーケンスがない、第1バイトを見ただけで文字種がわかることがあげられます。
その反面短所として、拡張性にとぼしい、第2バイトに含まれる0x40~0x7Eのコード(特に、ASCII のバックスラッシュにあたる0x5C)が問題となる場合があること、MSB が落ちたときの復元が困難なことなどがあげられます。
なお、JIS X 0208-1997 ではシフト JIS の規定が取り入れられましたが、この中で、シフト JIS の X 0201 カタカナは将来廃止して、そのコード空間を漢字の拡張にあてる旨の方向性が示されています。
e.g. 文字列「かな漢字a」をシフトJISで符号化すると次のようになります。
| 文字列 | かな漢字a |
| エスケープシーケンス | 存在しない |
| コード値 | 82A9 82C8 8ABF 8E9A 61 |
| ASCII文字 | ........a |
※ASCII文字で表示できないコードは"."とした
第5章 EUC
EUCは、UNIXの日本語環境でよく使われるコード体系です。
EUC は、Extended UNIXCode の略で、UNIX の多言語対応の一環として制定されました。EUC には、日本語 EUC の他に中国語 EUC、韓国語 EUC などもあります。日本語 EUC のことを UJIS(Unixized JIS)とも呼びます。
EUCは ISO 2022 に準拠したエンコーディング法で、8単位系の符号空間(インユーステーブル(in-use table))と、G0 から G3 までの4つの中間バッファを持ち、大半の日本語対応 UNIX ワークステーションの内部コードとして使われています。日本語 EUC ではインユーステーブルおよび中間バッファを固定的に次のように使用しています。
- G0 に ASCII(またはJIS X 0201 ローマ文字)を指示
- G1 に JIS X 0208 漢字を指示
- G2 に JIS X 0201 カタカナを指示
- G3 に JIS X 0212 補助漢字を指示
- G0 を GL に、G1 を GR に呼び出す
- G2 と G3 はシングルシフトで使用
- エスケープシーケンス・ロッキングシフトは使わない
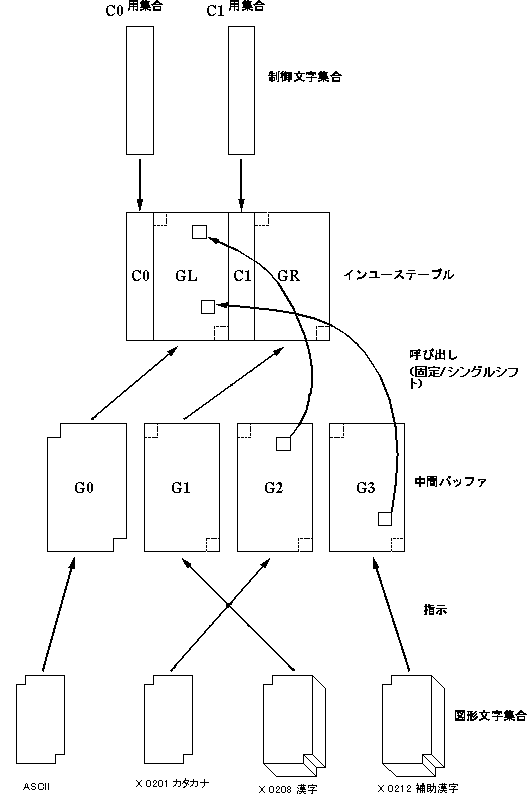
図5-1 EUCエンコーディング の構造
EUCでは X 0208 は第1バイトと第2バイトの MSB が1になりますが、これは単に ASCII と区別するために適当にそうしているのではなく、ISO 2022 の枠組みに沿って符号化した結果というわけです。カタカナや補助漢字に付く 0x8E/0x8F のプレフィクスも、ISO 2022 のシングルシフトに由来しています。つまり、いわゆる半角カタカナ文字は、0x8Eのプレフィクス付きの2バイトコードになっています。また、補助漢字も 0x8F のプレフィクス付きの3バイトコードになります。
EUC の一般的な構成として、ASCII(またはISO 646)を含めて4つまでの文字集合を扱うことができます。これらは ISO 2022 で定義される G0 ~ G3 に指示されています。特に、G0 には ASCII(ISO 646)、G1 にはその言語でもっともよく使う文字集合(ASCII以外)が指示されており、これらはそれぞれ GL と GR に呼び出されています。指示および呼び出しは固定されており、エスケープシーケンスやロッキングシフトで変更されることはありません。さらに、補助的に用いる文字集合を G2 と G3 に指示することができ、これらはシングルシフトによって呼び出されます。指示・呼び出しが固定なので、文字列を解釈または生成する際、現在どの文字集合が指示されているかといったような「状態」情報を保持する必要がない(stateless, modeless)ことが大きな特徴となっています。
長所をまとめると、エスケープシーケンスがない、第1バイトを見ただけで文字種がわかる、漢字の第2バイトが ASCII と重複しない、JIS とのコード変換が容易であることがあげられます。
その反面短所として、バイト数は半角カタカナや補助漢字まで考慮すると複雑となる、G0 から G3 を固定的に使用しているため拡張性に限界があることがあげられます。事実、EUC を採用したシステムでも、補助漢字までサポートしている例は非常に少なく、半角カタカナのサポートもつい最近まではなおざりにされていました。
e.g. 文字列「かな漢字a」を EUC に従い符号化すると次のようになります。
| 文字列 | かな漢字a |
| エスケープシーケンス | 存在しない |
| コード値 | A4AB A4CA BAC1 BBFA 61 |
| ASCII文字 | ........a |
※ASCII文字で表示できないコードは"."とした
参考文献
各種規格・標準
- JIS X 0201-1976
- JIS X 0208-1997
- JIS X 0212-1990
- ISO 2022, JIS X 0202-1990
書籍・マニュアル
- Ken Lunde 『日本語情報処理』、春遍雀來・鈴木武生訳、ソフトバンク、1995年 ISBN 4-89052-708-7
電子化文書
- 文字コードの話 (1998.5.5 link 承諾受)
- RFC 1468: Japanese Character Encoding for Internet Messages (ISO-2022-JP)