第5章 EUC
EUCは、UNIXの日本語環境でよく使われるコード体系です。
EUC は、Extended UNIXCode の略で、UNIX の多言語対応の一環として制定されました。EUC には、日本語 EUC の他に中国語 EUC、韓国語 EUC などもあります。日本語 EUC のことを UJIS(Unixized JIS)とも呼びます。
EUCは ISO 2022 に準拠したエンコーディング法で、8単位系の符号空間(インユーステーブル(in-use table))と、G0 から G3 までの4つの中間バッファを持ち、大半の日本語対応 UNIX ワークステーションの内部コードとして使われています。日本語 EUC ではインユーステーブルおよび中間バッファを固定的に次のように使用しています。
- G0 に ASCII(またはJIS X 0201 ローマ文字)を指示
- G1 に JIS X 0208 漢字を指示
- G2 に JIS X 0201 カタカナを指示
- G3 に JIS X 0212 補助漢字を指示
- G0 を GL に、G1 を GR に呼び出す
- G2 と G3 はシングルシフトで使用
- エスケープシーケンス・ロッキングシフトは使わない
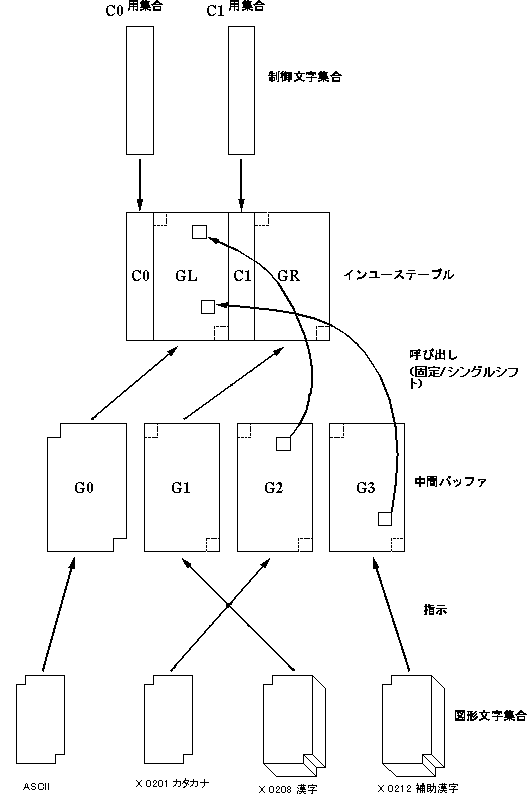
図5-1 EUCエンコーディング の構造
EUCでは X 0208 は第1バイトと第2バイトの MSB が1になりますが、これは単に ASCII と区別するために適当にそうしているのではなく、ISO 2022 の枠組みに沿って符号化した結果というわけです。カタカナや補助漢字に付く 0x8E/0x8F のプレフィクスも、ISO 2022 のシングルシフトに由来しています。つまり、いわゆる半角カタカナ文字は、0x8Eのプレフィクス付きの2バイトコードになっています。また、補助漢字も 0x8F のプレフィクス付きの3バイトコードになります。
EUC の一般的な構成として、ASCII(またはISO 646)を含めて4つまでの文字集合を扱うことができます。これらは ISO 2022 で定義される G0 ~ G3 に指示されています。特に、G0 には ASCII(ISO 646)、G1 にはその言語でもっともよく使う文字集合(ASCII以外)が指示されており、これらはそれぞれ GL と GR に呼び出されています。指示および呼び出しは固定されており、エスケープシーケンスやロッキングシフトで変更されることはありません。さらに、補助的に用いる文字集合を G2 と G3 に指示することができ、これらはシングルシフトによって呼び出されます。指示・呼び出しが固定なので、文字列を解釈または生成する際、現在どの文字集合が指示されているかといったような「状態」情報を保持する必要がない(stateless, modeless)ことが大きな特徴となっています。
長所をまとめると、エスケープシーケンスがない、第1バイトを見ただけで文字種がわかる、漢字の第2バイトが ASCII と重複しない、JIS とのコード変換が容易であることがあげられます。
その反面短所として、バイト数は半角カタカナや補助漢字まで考慮すると複雑となる、G0 から G3 を固定的に使用しているため拡張性に限界があることがあげられます。事実、EUC を採用したシステムでも、補助漢字までサポートしている例は非常に少なく、半角カタカナのサポートもつい最近まではなおざりにされていました。
e.g. 文字列「かな漢字a」を EUC に従い符号化すると次のようになります。
| 文字列 | かな漢字a |
| エスケープシーケンス | 存在しない |
| コード値 | A4AB A4CA BAC1 BBFA 61 |
| ASCII文字 | ........a |
※ASCII文字で表示できないコードは"."とした